ScaleArc is a database load balancer and website performance accelerator. It enables database administrators to create highly available, scaleable — and easy to manage, maintain and migrate — database deployments.
ScaleArc works with Microsoft SQL Server and MySQL as an on-premise solution, within the cloud for corresponding PaaS or as DBaaS solutions including Amazon RDS or AzureSQL.
Why ScaleArc?
- Get to the cloud faster
- Build cloud-native apps faster
- Scale out with no code changes
- Achieve continuous availability
- Enable active/active architectures
- Simplify and speed up database maintenance, patches and upgrades
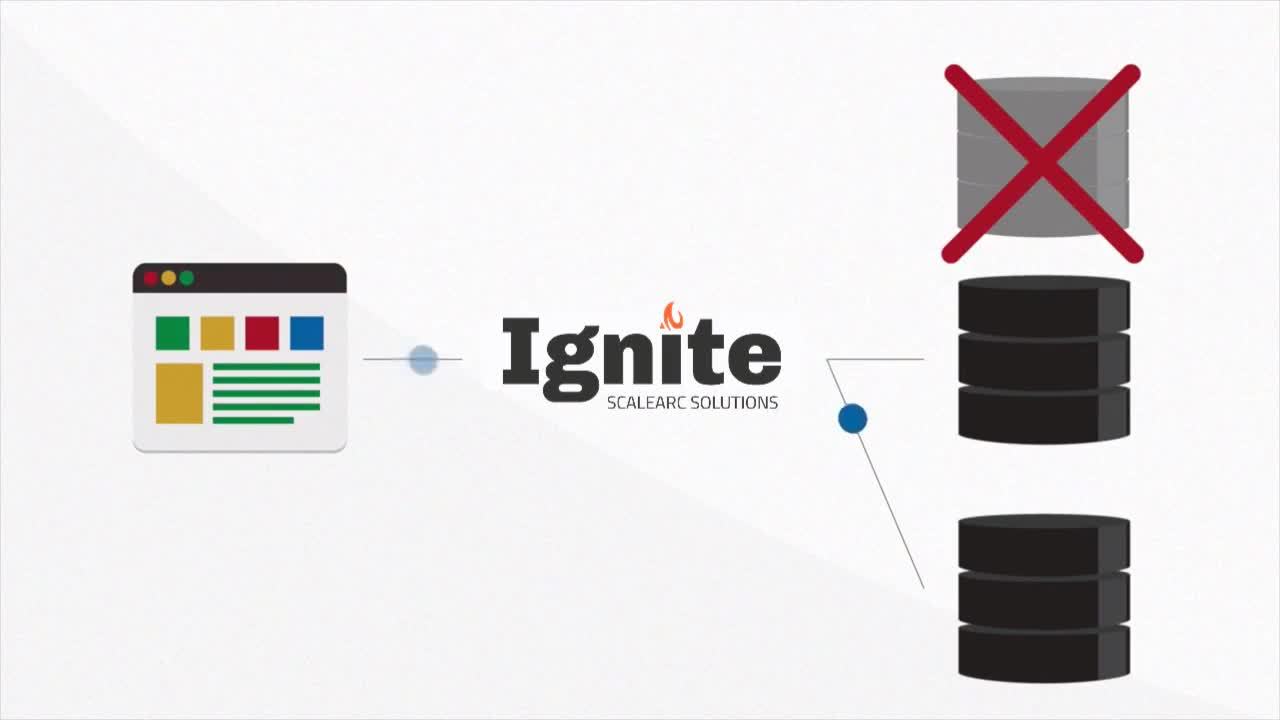
SCALEARC IN ACTION
- Build highly available database environments.
- Enable uptime, performance and scale for your critical apps in a database environment.
- Ensure zero downtime during database maintenance and reduce risk of unplanned outages, by automating failover processes and intelligently redirecting traffic to database replicas.
- Effectively balance read and write traffic to dramatically improve overall database throughput.
- Consolidate database analytics into a single platform, allowing administrators and production support to make more efficient and intelligent decisions — saving time and money.
- Seamlessly migrate to the cloud and between the platforms without incurring application downtime.
NEW GENAI COPILOT FEATURE
ScaleArc CoPilot is a GenAI personal assistant designed to improve ScaleArc’s user experience. Deployed as an add-on, CoPilot integrates directly into the admin console, providing instant assistance on procedures, performance metrics, and security monitoring. With its GenAI-powered chatbot, administrators receive real-time guidance, streamlining tasks and minimizing the need for external resources.
FEATURES
Instant Guidance on Procedures: ScaleArc CoPilot ensures you receive step-by-step assistance for core administrative tasks, whether it's setting up clusters or adding nodes.
On-demand performance metrics: CoPilot, equipped with real-time analytics, promptly delivers system metrics, offering insights into areas like CPU usage and overall system health.
Optimization Suggestions: Leveraging the power of GenAI, CoPilot proactively provides system optimization tips, ensuring configurations are at their peak performance.
BENEFITS
Minimize Downtime: Instant responses from CoPilot ensure that your systems run smoothly and disruptions are quickly addressed.
Reduce Support Costs: Decrease reliance on external support, letting CoPilot handle many queries and issues internally.
Empower New Team Members: Speed up the onboarding process for new administrators with an always-on assistant to answer questions and guide tasks.

NASDAQ CUSTOMER SUCCESS
Watch the video to see how ScaleArc powers Nasdaq.



Resources







COMPLEMENTARY IGNITETECH UNLIMITED SOLUTIONS
Check out the solutions below, available free as part of your ScaleArc subscription:
FogBugz
FogBugz
Plan, track and release great software with this lightweight and customizable system that seamlessly integrates into any project management workflow.
Kayako
Kayako
Deliver exceptional customer service in multiple languages across live chat, email, Facebook and Twitter.
Blog Posts

Jul 20, 2022
FogBugz and ScaleArc Transition to IgniteTech
IgniteTech today announced a transition of two software products from the ESW Capital portfolio to…

Jul 12, 2022
DNN Connect 2022: A trip report
Brad Mills, Chief Product Officer at IgniteTech, details his experience at the DNN Connect 2022…

Jul 1, 2022
The 3 Biggest Developments in Enterprise Cloud Today (and Why They're a Big Deal)
Get the top 3 developments in enterprise cloud and see how you can get updates on them for driving…

May 23, 2022
3 Things Enterprise Tech Leaders Need To Prioritize in 2022 and Beyond
To meet succeed in today’s turbulent business environment, enterprise tech leaders need to…

Jul 15, 2019
How Infobright's Columnar Database Supercharges Decision Making and Supports Organizational Agility
Enterprises are moving away from conventional OLTP relational databases in search of more convenient…

Mar 7, 2019
How an Event Data Warehouse Helps Meet Compliance Demands
Event data warehouse solutions are essential to meeting today’s compliance demands, helping…